
自分のブログの記事一覧をPythonでスクレイピングしてみた2.実際のコード
目次
今回の対象範囲の確認
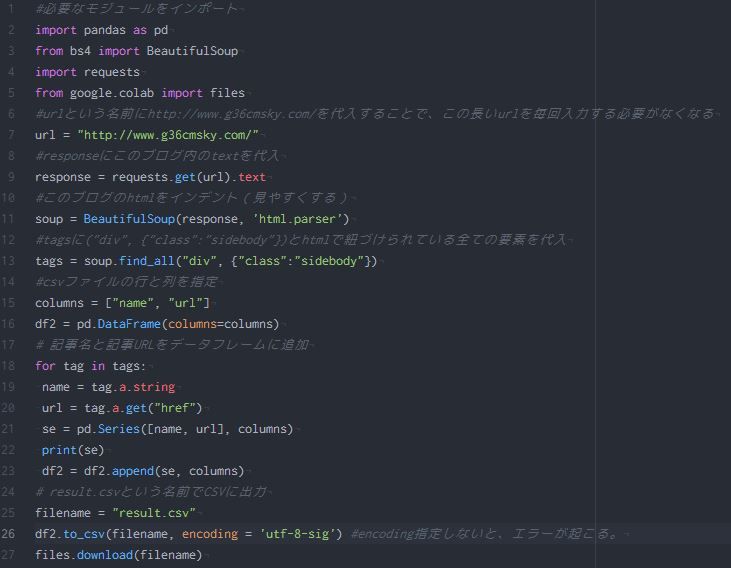
urlという名前にこのブログのURLを代入
responseにこのブログ内のtextを代入
BeautifulSoupの初期化
tagsに("div", {"class":"sidebody"})とhtmlで紐づけられている全ての要素を代入
csvファイルの行と列を指定
記事名と記事URLをデータフレームに追加
result.csvという名前でCSVに出力
あとがき
今回の対象範囲の確認
urlという名前にこのブログのURLを代入
responseにこのブログ内のtextを代入
BeautifulSoupの初期化
tagsに("div", {"class":"sidebody"})とhtmlで紐づけられている全ての要素を代入
csvファイルの行と列を指定
記事名と記事URLをデータフレームに追加
result.csvという名前でCSVに出力
あとがき
今回の対象範囲の確認
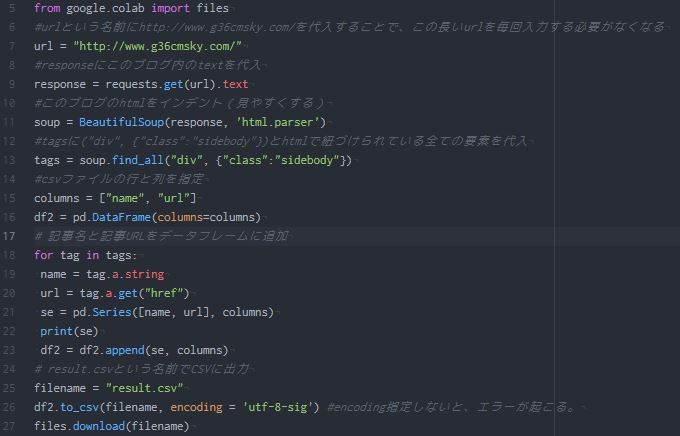

urlという名前にこのブログのURLを代入
とすることで、これから自分のブログのURLを使いたいときに毎回入力する手間を、urlという三文字で置き換えました。楽になりますね。
responseにこのブログ内のtextを代入
とすることで、「url」内のtextを取得することができます。
復習ですが、「requestsはWebからデータをダウンロードできるライブラリです。」
「.get()」
Webからデータを取得する際に、どこのWebsiteにアクセスするかを決めるときに「.get()」を使います。「.get」の後に取得したいWebのURLを入力します。僕のブログにアクセスしたいので、僕のブログのURLを入力します。この前に「url = "http://www.g36cmsky.com/"」としたことが役に立ちます。urlという文字が僕のブログのURLと同じ意味になっているので、「.get(url)」でいいのです。「url = "http://www.g36cmsky.com/"」としていなかった場合は、「.get("http://www.g36cmsky.com/")」としなければなりません。
BeautifulSoupの初期化
とすることで、BeautifulSoupの初期化を行います。
ここではHTMLを扱っているので、BeautifulSoupが使われています。
tagsに("div", {"class":"sidebody"})とhtmlで紐づけられている全ての要素を代入
ここでは、tagsに僕のブログの横にずらーっと並んでいる要素を取り込んでいます。(「取り込んでいる」という表現が適切かは怪しいところですが。。。)
ここでも、扱っているのはHTMLなのでBeautifulSoupを使っています(soupって書いてあるところね。)。soupの後ろにある「.fund_all」はざっくり言うと「全部出せ」といったところでしょうか。何を全部出すかというと、さらにその後ろにある("div", {"class":"sidebody"})です。
つまり、ここで書いたコードは
「HTML内にある("div", {"class":"sidebody"})という要素を全部出して。」という意味になります。
csvファイルの行と列を指定
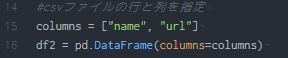
columnsにデータフレーム(目的であるCSVファイルの中の列)を作ります。その名前がnameとurlになります。このnameの下には記事のタイトルがずらーっと並び、urlの下には各URLがずらーっと並ぶ予定です。
df
dfとされていてこれ何か意味があるのかなと思いましたが、たぶんなんでもいいです。ただ、 pandasでググるとほとんどdfの中にしまわれていました。これはたぶん、 data frameの略でdfになっているんだろうなあと勝手に納得しています。違っていたら教えてもらえれば幸いです。pd(pandas)
最初にpandasをインポートした時に、pandas as pdとしました。よってこのpdはpandasの意味です。.DataFrame
.DataFrameはpandasのコマンドで、データフレームを作成するときに使います。今回は列を作るので、DataFrame(columns=columns)とします。最初のcolumnsが列を指定して、次のcolumnsは自分が前に作成した「columns = ["name", "url"]」のことです。記事名と記事URLをデータフレームに追加
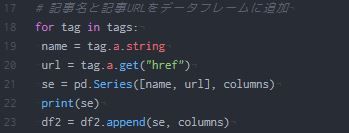
for文について
for文はループ(繰り返し)処理を行う時に使われる文です。for文はPythonだけでなく他の様々なプログラミング言語でも使われています。for文を使って、僕のブログの複数ある記事タイトル、URLを取得しようというわけです。in演算子
for文で使われているin演算子は、一つずつ取り出すときに使われるようです。実際に書いたfor文
tagsの中からtagの中に繰り返し、一つずつ要素を取り出す
「for tag in tags:」
は、tagsの中からtagの中に繰り返し、一つずつ要素を取り出す。という意味です。この文の下には、取り出した要素を格納します。具体的に言うと、前に作成したCSVの列名name、urlにtagsの中の各タイトル、URLを格納していきます。
nameにtag内にあるaタグ要素の文字列のみを取り出す
urlにtag内にあるa要素のhref要素を取りだす
はurlにtag内にあるa要素のhref要素(URLが書かれているところ)のみを取り出します。という意味です。
seにpandasを使いSeriesという型にデータを収納
はseにpandasを使って、Seriesという型にデータを収納します。ここで収納するデータは、[name, url]というデータと前に作成したcolumnsのデータです。
seの表示
以前に作成したdf2に今回作成したseを追加
.appendで要素を追加
result.csvという名前でCSVに出力

