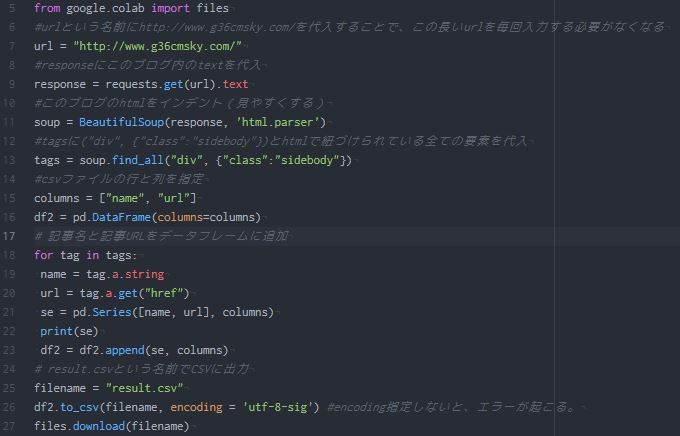
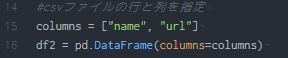
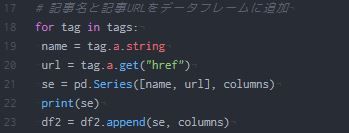
【Linux エラー】ロック /var/lib/dpkg/lck-frontendが取得できませんでした
Linuxでアプリをインストールしようといつもどおりsudo apt-get install hogehogeとしていたらエラーメッセージが出てインストールできませんでした。
こういう時はとりあえずエラーメッセージをコピペしてググると解決作が出るものですね。
ts0818さんのブログ『ロック /var/lib/apt/lists/lock が取得できませんでした~』を参考にしました。
詳しいことはわからないのですが、lock fileというのを取り除けばいいっぽい。 ということでターミナルを開いて、hogehogeが取得できませんでしたのところをrmでリムーブしてやればいいみたいです。 実際にその後はインストールできました。
関連記事
Latex関連
Latexプリアンブル設定:%、イタリックのフォントが微妙だったので変えてみた。
Latexコマンドメモ。上付き文字 下付き文字、℃、化学式、学名のイタリック体、μ。
無料文献管理ソフトMendeleyとLatexの連携で引用文献リストの自動化
Linux エラー】ロック /var/lib/dpkg/lck-frontendが取得できませんでした
Latexエラー:“Extra }, or forgotten \endgroup”